Nov '96 ASME Paper re:
EXTREMELY LARGE SCALE BROADCAST FACILITIES
ABSTRACT
The advent of Direct Broadcast Satellites requires the associated development of origination facilities supporting hundreds of viewer channels. Such facilities use highly automated, fault tolerant control systems to facilitate cost-effective staffing levels and the flexibility to support services that are only now evolving.
We summarize the capabilities and architecture of two such facilities that are among the largest in the world: the more than 175 channel DIRECTV® Castle Rock Broadcast Center (CRBC) servicing the continental United States from Colorado, and the 72 channel DIRECTV International Inc. California Broadcast Center in Long Beach servicing Latin America and the Caribbean. For program transmission, these services use the latest, high-powered Hughes Ku-band communication satellites. For program playback, each plant uses relatively conventional digital tape-based technology. Two factors make the program playout operations unique. First, their extreme size and scope. Second, all the resources in the plant are sharable and schedulable among different viewer channels to assure the plant can adapt to the services demanded by their evolving market. Some "lessons learned" are then discussed as suggestions to aid future product and facility developments.
DIRECTV'S CASTLE ROCK BROADCAST CENTER (CRBC)
In October 1992, Sony Electronics Inc. was awarded an approximately $50M contract from Hughes Communications Inc. to provide the Baseband Video Subsystem of the DIRECTV® origination facility in Castle Rock, Colorado. The plant contains about 275 of Sony's new Digital Betacam video tape machines, most of which are housed in 56 tape robots. Other major elements include one large and six small edit suites used to quality check and prepare the program and promotional material for air as well as the largest digital broadcast router in the world. Physically, this is a 512 by 512 matrix but is logically combined with other video/audio, digital/ analog routers to support a virtual 1048 by 760 matrix. Essentially, these routers are extremely fast switches that can connect any input to the matrix with any subset of the outputs. Analog inputs to the facility are received over fiber feeds or from a farm of large satellite dishes and are then conditioned and converted to the 270 Megabits per second (Mbps) Serial Digital Interface (SMPTE Standard 259M) data for internal distribution within the plant. The router is then routinely switching any arbitrary combination of about 20 Terabytes per second of digital video and audio glitch-free.
While Sony can be justifiably proud that over $20M of the hardware carries their logo, $15M of non-Sony hardware provided under the contract was also integrated. Both the Sony and third party equipment was interfaced to the other substantial subsystems contracted directly by Hughes from others, e.g., the high-powered amplifiers and the four 13 meter uplink dishes, the conditional access equipment providing encryption and enabling convenient pay per view, business systems such as electronic program guides, billing, etc., as well as the key video compression technology, all housed in this $100+M facility. To maximize video quality and minimize development risk, the facility uses minimal compression internally. However, reducing the data rate from 270 Mbps to about 4-8 Mbps just before output using MPEG-2 is key to getting several channels of high quality video and audio programming over a satellite transponder that would normally support just one.
Figure 1 shows the major functional blocks of the facility broadcast control subsystem. As with the hardware, several key elements of the control software were purchased and integrated, mainly related to the low-level machine control. Custom software was required primarily to provide two functions: a) enable the centralized operator control of all subsystems, and b) error monitoring and associated automated takeover by backup devices, now commonly from a sharable pool. Various interfacing computers (IC's) were provided and typically store, forward, and translate from the semantics of the source to that of the receiver. This approach reduces the amount and localizes the scope of customization.
CRBC began revenue operations in June 1994 and has subsequently acquired over 1.7 million purchasers of the pizza sized (about 0.5 meter) dishes and set-top receivers. More than 175 channels are routinely provided with increasingly diverse content. Typical are 60 for pay-per-view movies, another 60 "turn-arounds" like CNN, 30 regional sports, 30+ music, and several special interest channels.
DIRECTV INTERNATIONAL INC.'S CALIFORNIA BROADCAST CENTER
Two years later, a second facility was contracted to service Latin America and the Caribbean from Long Beach, California for 72 channels of movies and turn-arounds. Three regional broadcast centers in Mexico, Brazil, and Venezuela will originate locally focused channels (18-40 each) that are also then uplinked to the satellite. The Long Beach facility is essentially a half-size clone of Castle Rock. Principle changes include less use of robotics and a Sony scheduling subsystem. Revenue service began in July 1996.
FURTHER EVOLUTIONS
Figure 2 summarizes the key traits of these facilities. The second facility's usage model led to a reduction in the number of tape robots. At the CRBC, the vagaries of live sporting events is leading to the use of new RAID-based video server technology. Sports typically involves much content commonality, a small total quantity, but are very dynamic (read that unschedulable) situations where operators need lots of flexibility. Tape remains the cheapest digital storage medium, but only the new non-linear hard disk drive video server systems trivially enable operators to play out several channels slightly shifted in time from a single storage source.
LESSONS LEARNED
The integration of the products and software from many suppliers used the common systems engineering practices originally typified by aerospace. For example, Interface Control Documents (ICD's) and Interface Control Working Groups (ICWG's) were used extensively and generally effectively. Infrequent issues were mainly the common reluctance by engineers to commit to an interface until they had completed their detailed design.
Many of the facility control challenges are related to dealing with live events. Initially, many involved thought that these facilities could be scheduled well in advance which is much easier to automate. Instead, sports led to a whole series of continuing enhancements. For example, when a game ends early, it's not enough to just switch the programming. You also have to change the conditional access so that new viewer eligibility is enabled and you have to change the electronic program guide to reflect the new schedule. You may also need to re-point an antenna, or change…
Dealing with pooled resources also leads to scheduling challenges. While many elements are deemed critical enough to warrant classical one-for-one redundancy, some subsystems are just too expensive. Over time, the demand for new services tended to cause even the resources that were originally one-to-one redundant to now use pooled backups. Further, there is great flexibility in being able to use any device, e.g., a tape recorder, to play out on any channel, but these choices must now all be scheduled and then automatically tested for resource conflicts across all the channels for the entire broadcast day, e.g., do we have enough copies of a movie, are we trying to use the same recorder to play two different tapes simultaneously, did we leave enough time for the tape to rewind before we play it again?, etc.
While there is obviously much focus on assuring reliable playout to air of the desired material, in fact, automating playout is only about one fourth of the total plant control problem. Facilities must be provided to receive master tapes from external entities, e.g., the movie studios; convert them to the house tape format and QA their quality and technical characteristics; make enough copies to support scheduling needs; move the copies from the media library to the correct playout machine and vice versa; make promotional videos, etc., etc., etc. Then, one needs to enable each operator to manage, say, 50 channels including the ability to centrally monitor and change any of the technical characteristics of all the hardware and software involved. Finally, one needs to automatically sense the health of hundreds of hardware and software elements, report warnings and errors, automatically switch to backup devices, and then suggest other devices that could be put in use to regain backup protection.
Fault tolerance needs to be architectural, not an add-on. These facilities are manned at less than 1 person per channel. Obviously, the operators must be allowed to focus on the exceptions only, and then usually in deciding what subsequent actions to take. While existing software applications were adapted wherever feasible with usable results, generally these were not designed (understandably) with systems of this degree of scope and automation in mind. Often, rather brute force duplication was the only practical solution.
A corollary is that software single points of failure should be avoided as least as stringently as hardware single points of failure. So-called "god" processes, i.e., a process that must be alive and functioning to enable other processes to continue their tasks, are particularly worrisome. Distributed, peer architectures appear more appropriate for such systems.
Finally, operators need access to and the ability to modify almost everything. Originally, some subsystems were designed under the premise that the person or process upstream never made a mistake. Even if they didn't (which they do), dealing with live events demands the ability to quickly, reliably, and confidently assess and change almost every technical characteristic in the facility. Much functionality was added to enable such so-called "Day of Air" changes. In fact, this capability was subsequently expanded as the foundation for the scheduling activities at the second site.
Acknowledgments
The Hughes team, headed by Dave Baylor, Steve Orland, and Ron Allen, led a large team of associate- and sub-contractors whom are sincerely appreciated for their supportive and effective contributions.
The advent of Direct Broadcast Satellites requires the associated development of origination facilities supporting hundreds of viewer channels. Such facilities use highly automated, fault tolerant control systems to facilitate cost-effective staffing levels and the flexibility to support services that are only now evolving.
We summarize the capabilities and architecture of two such facilities that are among the largest in the world: the more than 175 channel DIRECTV® Castle Rock Broadcast Center (CRBC) servicing the continental United States from Colorado, and the 72 channel DIRECTV International Inc. California Broadcast Center in Long Beach servicing Latin America and the Caribbean. For program transmission, these services use the latest, high-powered Hughes Ku-band communication satellites. For program playback, each plant uses relatively conventional digital tape-based technology. Two factors make the program playout operations unique. First, their extreme size and scope. Second, all the resources in the plant are sharable and schedulable among different viewer channels to assure the plant can adapt to the services demanded by their evolving market. Some "lessons learned" are then discussed as suggestions to aid future product and facility developments.
DIRECTV'S CASTLE ROCK BROADCAST CENTER (CRBC)
In October 1992, Sony Electronics Inc. was awarded an approximately $50M contract from Hughes Communications Inc. to provide the Baseband Video Subsystem of the DIRECTV® origination facility in Castle Rock, Colorado. The plant contains about 275 of Sony's new Digital Betacam video tape machines, most of which are housed in 56 tape robots. Other major elements include one large and six small edit suites used to quality check and prepare the program and promotional material for air as well as the largest digital broadcast router in the world. Physically, this is a 512 by 512 matrix but is logically combined with other video/audio, digital/ analog routers to support a virtual 1048 by 760 matrix. Essentially, these routers are extremely fast switches that can connect any input to the matrix with any subset of the outputs. Analog inputs to the facility are received over fiber feeds or from a farm of large satellite dishes and are then conditioned and converted to the 270 Megabits per second (Mbps) Serial Digital Interface (SMPTE Standard 259M) data for internal distribution within the plant. The router is then routinely switching any arbitrary combination of about 20 Terabytes per second of digital video and audio glitch-free.
While Sony can be justifiably proud that over $20M of the hardware carries their logo, $15M of non-Sony hardware provided under the contract was also integrated. Both the Sony and third party equipment was interfaced to the other substantial subsystems contracted directly by Hughes from others, e.g., the high-powered amplifiers and the four 13 meter uplink dishes, the conditional access equipment providing encryption and enabling convenient pay per view, business systems such as electronic program guides, billing, etc., as well as the key video compression technology, all housed in this $100+M facility. To maximize video quality and minimize development risk, the facility uses minimal compression internally. However, reducing the data rate from 270 Mbps to about 4-8 Mbps just before output using MPEG-2 is key to getting several channels of high quality video and audio programming over a satellite transponder that would normally support just one.
Figure 1 shows the major functional blocks of the facility broadcast control subsystem. As with the hardware, several key elements of the control software were purchased and integrated, mainly related to the low-level machine control. Custom software was required primarily to provide two functions: a) enable the centralized operator control of all subsystems, and b) error monitoring and associated automated takeover by backup devices, now commonly from a sharable pool. Various interfacing computers (IC's) were provided and typically store, forward, and translate from the semantics of the source to that of the receiver. This approach reduces the amount and localizes the scope of customization.
CRBC began revenue operations in June 1994 and has subsequently acquired over 1.7 million purchasers of the pizza sized (about 0.5 meter) dishes and set-top receivers. More than 175 channels are routinely provided with increasingly diverse content. Typical are 60 for pay-per-view movies, another 60 "turn-arounds" like CNN, 30 regional sports, 30+ music, and several special interest channels.
DIRECTV INTERNATIONAL INC.'S CALIFORNIA BROADCAST CENTER
Two years later, a second facility was contracted to service Latin America and the Caribbean from Long Beach, California for 72 channels of movies and turn-arounds. Three regional broadcast centers in Mexico, Brazil, and Venezuela will originate locally focused channels (18-40 each) that are also then uplinked to the satellite. The Long Beach facility is essentially a half-size clone of Castle Rock. Principle changes include less use of robotics and a Sony scheduling subsystem. Revenue service began in July 1996.
FURTHER EVOLUTIONS
Figure 2 summarizes the key traits of these facilities. The second facility's usage model led to a reduction in the number of tape robots. At the CRBC, the vagaries of live sporting events is leading to the use of new RAID-based video server technology. Sports typically involves much content commonality, a small total quantity, but are very dynamic (read that unschedulable) situations where operators need lots of flexibility. Tape remains the cheapest digital storage medium, but only the new non-linear hard disk drive video server systems trivially enable operators to play out several channels slightly shifted in time from a single storage source.
LESSONS LEARNED
The integration of the products and software from many suppliers used the common systems engineering practices originally typified by aerospace. For example, Interface Control Documents (ICD's) and Interface Control Working Groups (ICWG's) were used extensively and generally effectively. Infrequent issues were mainly the common reluctance by engineers to commit to an interface until they had completed their detailed design.
Many of the facility control challenges are related to dealing with live events. Initially, many involved thought that these facilities could be scheduled well in advance which is much easier to automate. Instead, sports led to a whole series of continuing enhancements. For example, when a game ends early, it's not enough to just switch the programming. You also have to change the conditional access so that new viewer eligibility is enabled and you have to change the electronic program guide to reflect the new schedule. You may also need to re-point an antenna, or change…
Dealing with pooled resources also leads to scheduling challenges. While many elements are deemed critical enough to warrant classical one-for-one redundancy, some subsystems are just too expensive. Over time, the demand for new services tended to cause even the resources that were originally one-to-one redundant to now use pooled backups. Further, there is great flexibility in being able to use any device, e.g., a tape recorder, to play out on any channel, but these choices must now all be scheduled and then automatically tested for resource conflicts across all the channels for the entire broadcast day, e.g., do we have enough copies of a movie, are we trying to use the same recorder to play two different tapes simultaneously, did we leave enough time for the tape to rewind before we play it again?, etc.
While there is obviously much focus on assuring reliable playout to air of the desired material, in fact, automating playout is only about one fourth of the total plant control problem. Facilities must be provided to receive master tapes from external entities, e.g., the movie studios; convert them to the house tape format and QA their quality and technical characteristics; make enough copies to support scheduling needs; move the copies from the media library to the correct playout machine and vice versa; make promotional videos, etc., etc., etc. Then, one needs to enable each operator to manage, say, 50 channels including the ability to centrally monitor and change any of the technical characteristics of all the hardware and software involved. Finally, one needs to automatically sense the health of hundreds of hardware and software elements, report warnings and errors, automatically switch to backup devices, and then suggest other devices that could be put in use to regain backup protection.
Fault tolerance needs to be architectural, not an add-on. These facilities are manned at less than 1 person per channel. Obviously, the operators must be allowed to focus on the exceptions only, and then usually in deciding what subsequent actions to take. While existing software applications were adapted wherever feasible with usable results, generally these were not designed (understandably) with systems of this degree of scope and automation in mind. Often, rather brute force duplication was the only practical solution.
A corollary is that software single points of failure should be avoided as least as stringently as hardware single points of failure. So-called "god" processes, i.e., a process that must be alive and functioning to enable other processes to continue their tasks, are particularly worrisome. Distributed, peer architectures appear more appropriate for such systems.
Finally, operators need access to and the ability to modify almost everything. Originally, some subsystems were designed under the premise that the person or process upstream never made a mistake. Even if they didn't (which they do), dealing with live events demands the ability to quickly, reliably, and confidently assess and change almost every technical characteristic in the facility. Much functionality was added to enable such so-called "Day of Air" changes. In fact, this capability was subsequently expanded as the foundation for the scheduling activities at the second site.
Acknowledgments
The Hughes team, headed by Dave Baylor, Steve Orland, and Ron Allen, led a large team of associate- and sub-contractors whom are sincerely appreciated for their supportive and effective contributions.
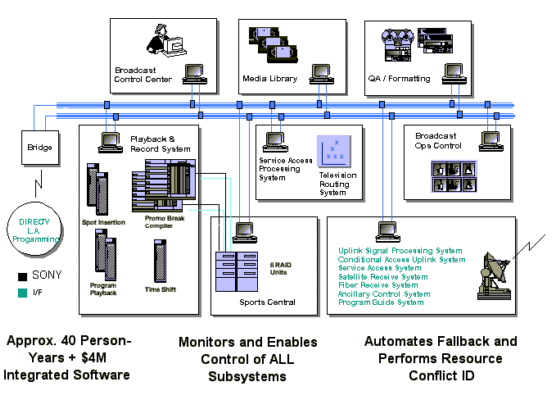
Figure 1: Major Functional Blocks
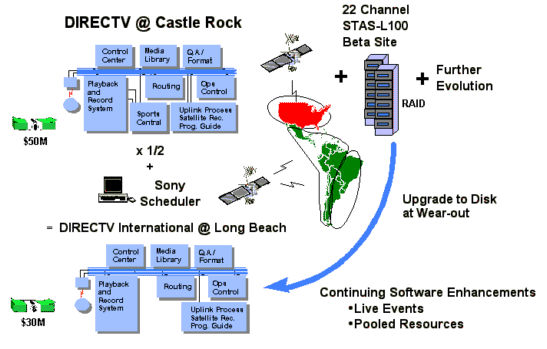
Figure 2: Key Facility Traits

Figure 3